摘要:摘要:在高比例新能源接入下,配置储能可以辅助电力系统削峰填谷,平抑波动。然而目前储能系统成本较高,需要政府进行支持。为此,提出了一种储能盈利策略,以在电网、储能运营商和
摘要:在高比例新能源接入下,配置储能可以辅助电力系统削峰填谷,平抑波动。然而目前储能系统成本较高,需要政府进行支持。为此,提出了一种储能盈利策略,以在电网、储能运营商和用户组成的电力市场中实现运营利润最大化。结合智能算法提出了一种考虑激励的盈利策略,为每个峰值时段的储能系统运营商提供不同权重的奖励分配。该算法一方面基于最小二乘支持向量机的深度学习,来建立价格和负荷预测模型;另一方面基于深度强化学习,考虑电网的峰值状态、用户负荷需求和储能系统运营商利润,确定最优充放电策略。最后通过案例分析,验证该策略可以显著提高储能系统运营商利润并减轻电网压力。
关键词:储能系统;盈利策略;支持向量机;深度强化学习算法
论文《基于深度强化学习算法的储能系统盈利策略研究》发表在《电力需求侧管理》,版权归《电力需求侧管理》所有。本文来自网络平台,仅供参考。
0 引言
新能源的广泛接入不断推动着我国能源向着清洁、低碳、可持续的方向发展。但风能、太阳能等新能源的波动性会导致并网后电网的电能质量不稳定,因此在我国出现大量的弃风弃光现象。
储能是我国能源主管部门非常认可的一种提高新能源利用效率和供电可靠水平的技术手段。由于储能成本高,需要结合电网运行控制要求,综合考虑各种因素,在系统建设过程中,结合经济投资限制、技术可靠性限制等因素对储能系统的盈利模式进行优化,最终确定合理的储能盈利策略。
文献[1-2]阐述了储能系统中的套利是一种通过在电价低时购买电力,在电价高时出售电力来追求利润的方法。文献[3-4]阐述了在传统电网中,储能主要用于可再生能源的负荷转移、调频和调峰。文献[5]阐述了在智能电网采用基于激励的需求响应的情况下,通过向用户支付激励来控制能源需求,将电网运营商的电力供应从高峰时段转移到非高峰时段。该激励综合套利策略通过转移电网的峰值负载,从而为储能系统运营商带来额外的利润。文献[6]应用强化学习来优化储能系统运营商的实时套利策略,该策略通过在不同价格场景下重复执行充电和放电操作来训练系统。
传统的基于模型[7]的方法受到未来不确定性和最优性的限制,这也直接影响了能源套利利润。数学模型难以预测未来电价和负荷需求,加上由于储能系统盈利实际环境的非平稳特性,储能系统运行的不确定性导致现有盈利策略无法保证盈利最优。
为更好地进行策略的应用,本文首先应用最小二乘支持向量机预测负荷和价格,其次考虑电网峰值状态、储能系统运营商利润和电网负荷需求,应用深度强化学习方法确定储能系统充电或放电的最优控制策略,实现储能系统运营商的利润最大化。
1 模型构建
本文提出的基于人工智能的储能系统盈利策略模型主要由电网、储能系统、用户3部分组成。对储能系统运营商来说,在电价低的时候系统进行充电,在电价高的时候进行放电,把电出售给用户。
1.1 储能系统运行模型
式(1)表示储能系统运营商通过交易能源资源在h时的套利收益:
R_h^{ ext{arbitrage}}=sum_{t=0}^{t_{max}}-p_tleft(frac{P_t^{ ext{cha}}}{eta^{ ext{cha}}}+P_t^{ ext{dis}}eta^{ ext{dis}}
ight) quad (1)
式中:tin{1,2,dots,t_{max}} 为要考虑的时间指标,t_{max} 为最后考虑的时间(即如果要考虑的数据为一天,则t_{max}=23);p_t 为时间段t时每单位电量的电价;P_t^{ ext{cha}}、P_t^{ ext{dis}} 分别为在每个时间步骤t从电网购买的电量和出售给用户的电量;eta^{ ext{cha}} 与 eta^{ ext{dis}} 分别为储能系统充放电效率。
由于充电过程中考虑到充电损耗,需要购买更多。另外,充电和放电不能在每个时间步同时发生。如果某一时间步没有充放电量,则充放电量设置为0。
在确定每个时间段的充放电功率时,必须考虑储能系统的电荷状态(state of charge, SOC)来维持储能的耐久性[8]。时间段t处的SOC由上一时间段t-1的SOC值和充放电功率大小决定,如式(2)所示,常数C^{ ext{ESS}} 为储能系统的总容量。式(3)为SOC的范围,S_{ ext{OC_min}} 和 S_{ ext{OC_max}} 分别为SOC的上下限。如果S_{ ext{OC_t}} 偏离这些边界,则会对储能的持久性产生不利影响,因此储能操作必须在此范围内:
S_{ ext{OC_t}}=S_{ ext{OC_{t-1}}}+frac{1}{C^{ ext{ESS}}}left(P_t^{ ext{cha}}eta^{ ext{cha}}-frac{P_t^{ ext{dis}}}{eta^{ ext{dis}}}
ight) quad (2)
S_{ ext{OC_min}} < S_{ ext{OC_t}} < S_{ ext{OC_max}} quad (3)
1.2 激励
本文中的“激励”[9]定义为:激励因子varphi_t 乘以每小时的电力套利利润所得的值。式(4)表示考虑了激励因子varphi_t 的激励收益。式(5)将激励因子varphi_t 定义为弹性xi_t 的函数,如下所示:
R_h^{ ext{stimul}}=sum_{t=0}^{t_{max}}-varphi_t p_tleft(frac{P_t^{ ext{cha}}}{eta^{ ext{cha}}}+P_t^{ ext{dis}}eta^{ ext{dis}}
ight) quad (4)
varphi_t = 1 - xi_t quad (5)
1.3 成本
储能系统在运行期间由于充放电会产生运营成本和回收成本[10]。系统运营维护成本如式(6)所示,储电成本如式(7)所示:
C_{ ext{yw}} = C_{ ext{rg}} + C_{ ext{cd}} quad (6)
C_{ ext{cd}} = P Q quad (7)
式中:C_{ ext{yw}} 为储能系统运营维护成本;C_{ ext{rg}} 为人工成本;C_{ ext{cd}} 为储电成本;P为储电价格;Q为储电量。人工成本主要为储能系统维护工人的工资、福利以及相应补贴等。
回收成本C_{ ext{hs}} 可表示为式(8):
C_{ ext{hs}} = lambda C_{ ext{gm}} quad (8)
式中:C_{ ext{hs}} 为储能系统的回收成本;lambda 为回收系数;C_{ ext{gm}} 为储能系统的购置成本。
总成本C_{ ext{all}} 表示储能系统总成本,表示为式(9):
C_{ ext{all}} = C_{ ext{yw}} + C_{ ext{hs}} quad (9)
1.4 目标函数
因此该模型的目标是同时考虑套利收益R_h^{ ext{arbitrage}}、激励收益R_h^{ ext{stimul}}和总成本,通过最优功率交易实现利润最大化,如式(10)所示。为了确认激励的效果,对有和没有激励收益R_h^{ ext{stimul}}的情况进行了对比研究:
maxleft(R_h^{ ext{arbitrage}} + R_h^{ ext{stimul}}
ight) - C_{ ext{all}} quad (10)
式中:R_h^{ ext{arbitrage}} 为储能系统运营商的套利收益;R_h^{ ext{stimul}} 为储能系统运营商的激励收益。
2 储能系统功率优化模型
2.1 决策过程
(1) 状态公式:环境状态设置为每个时间段的电价和SOC,如式(11)所示,p_t 是每个时间段的预测电价t,它将被代入第四步,S_{ ext{OC_t}} 是每个时间段储能系统的SOC值,它将影响储能系统运营商的行动。
s_t = left[p_t, S_{ ext{OC_t}}
ight] quad (11)
(2) 行动制定:储能系统的行为式(12)所示,它表示储能系统的充放电功率。这一行为范围处在最大放电功率P^{ ext{dis}} 和最大充电功率P^{ ext{cha}} 之间,如式(13)所示。该行为放电时为负值,充电时正值,空载时为0。P^{ ext{dis, max}} 和 P^{ ext{cha, max}} 的值取决于储能系统的值取决于储能系统的设计条件:
a_t = left[p_t
ight] quad (12)
a_t in left[P^{ ext{dis, max}}, P^{ ext{cha, max}}
ight] quad (13)
(3) 为了在充电和放电期间保持储能系统的耐用性,储能系统运营商在采取行动后的下一个时间步骤(t+1)中获得的即时奖励r_{t+1} 如式(14)所示:
r_{t+1} = r_{t+1}^{ ext{arbitrage}} + r_{t+1}^{ ext{stimul}} + r_{t+1}^{ ext{SOC}} quad (14)
式中:r_{t+1}^{ ext{arbitrage}} 为通过充电和放电之间的价格差异获得的套利奖励;r_{t+1}^{ ext{stimul}} 为来自电网的激励奖励;r_{t+1}^{ ext{SOC}} 为与SOC状态相关的奖励,该状态受到在环境中执行行动的储能系统运营商的影响。
套利奖励r_{t+1}^{ ext{arbitrage}} 和激励奖励r_{t+1}^{ ext{stimul}} 定义为式(15)和式(16)。与SOC状态相关的奖励r_{t+1}^{ ext{SOC}} 定义为式(17),其中r_{t+1}^{ ext{SOC}} 表示为:当SOC在边界范围内时,提供奖励系数F^{ ext{reward}},当SOC超出边界范围时,施加惩罚系数F^{ ext{penalty}}。随着F^{ ext{penalty}} 加大,SOC会逐渐回到边界中。在本研究中,F^{ ext{reward}} 设置为0,F^{ ext{penalty}} 设置为-50000。
r_{t+1}^{ ext{arbitrage}} = -p_tleft(frac{P_t^{ ext{cha}}}{eta^{ ext{cha}}} + P_t^{ ext{dis}}eta^{ ext{dis}}
ight) quad (15)
r_{t+1}^{ ext{stimul}} = -varphi_t p_tleft(frac{P_t^{ ext{cha}}}{eta^{ ext{cha}}} + P_t^{ ext{dis}}eta^{ ext{dis}}
ight) quad (16)
r_{t+1}^{ ext{SOC}} = �egin{cases} F^{ ext{reward}} & (S_{ ext{OC_min}} < S_{ ext{OC_t}} < S_{ ext{OC_max}}) \ F^{ ext{penalty}} & (S_{ ext{OC_t}} leqslant S_{ ext{OC_min}} ext{ or } S_{ ext{OC_t}} geqslant S_{ ext{OC_max}}) end{cases} quad (17)
2.2 Q-学习算法
Q-学习算法[11]通过对函数Q(s_t, a_t) 进行估计来求得最优策略。其中Q(s_t, a_t) 是当前状态s_t 下,执行动作a_t 获得的累计回报值。
式(18)定义的Q函数是运营商在状态s_t 执行行动时未来的预期总回报,其中E表示期望。最优策略表示为式(19):
Q(s_t, a_t) = Eleft[G_t mid s_t, a_t
ight] quad (18)
pi^*(s) = underset{a}{operatorname{argmax}} Q(s, a) quad (19)
式中:pi^*(s) 为状态s中的最佳策略。
最优策略pi^(s) 的Q函数Q^{pi^}(s_t, a_t) 可以用式(20)中的最优方程表示,A_{t+1} 是在t+1时刻可以执行的一系列动作:
Q^{pi^}(s_t, a_t) = Eleft[r_{t+1} + gamma max_{a_{t+1} in A_{t+1}} Q^{pi^}(s_{t+1}, a_{t+1}) mid s_t, a_t
ight] quad (20)
式中:gamma in [0,1] 为折现因子,将未来的奖励转化为当前的奖励的因子。在本研究中,应用式(21)所示的Q学习方法,基于状态-动作转换(s_{t+1}, a_{t+1}) 更新Q函数,并找到最优策略,如式(21)所示:
Q(s_t, a_t) leftarrow Q(s_t, a_t) + alphaleft[r_{t+1} + gamma max_{a_{t+1} in A_{t+1}} Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t)
ight] quad (21)
式中:alpha in [0,1] 为学习速率,它决定了估计结果的反映程度。
3 价格和负荷预测模型
3.1 模型构建
本节的数据量较小,但各影响因素与负荷之间的关系复杂,因此,利用最小二乘支持向量机[12]可以实现更好的预测效果。其主要原理如下。
对于一个样本的集合:S=(x_i, y_i)_{i=1}^L, x_i in X in R^n 表示输入向量,y_i in R 表示样本输出值,学习机可表示为如下决策函数,如式(22)所示:
f(x) = omega^T varphi(x) + b quad (22)
式中:varphi(x) 为x_i in X in R^n 映射到高维空间中的线性可分的非线性高维映射;omega 为权值向量;b为偏置值向量。构造结构风险函数如式(23)所示:
R = frac{1}{2}\omega
^2 + frac{1}{2} c R_{ ext{emp}} quad (23)
式中:$\omega
为控制模型的复杂程度;c为正则化参数;R_{ ext{emp}}$ 为经验风险。
在支持向量机(SVM)模型建模过程中R_{ ext{emp}} = sum_{i=1}^L e_i^2,则最小化结构风险的优化问题可表示为式(24)和式(25):
min R = frac{1}{2}omega^T omega + r sum_{i=1}^L e_i^2 quad (24)
ext{s.t. } y_i = omega_i varphi(x_i) + b + e_i quad (25)
式中:e为预测误差值;r为惩罚因子。SSA-LSSVM将上述公式转化为式(26)和式(27),提高求解速度:
min R = frac{1}{2}omega^T omega + frac{1}{2} c sum_{i=1}^L zeta_i^2 quad (26)
ext{s.t. } y_i = omega_i varphi(x_i) + b + zeta_i quad (27)
式中:zeta_i 为误差松弛变量,i=1,2,dots,L。
运用Lagrange乘子和对偶变换方法对规划优化问题进行变换,整理得到下述方程组,如式(28)所示:
�egin{cases} omega_i - lambda_i varphi(x_i) = 0 \ sum_{i=1}^L lambda_i = 0 \ lambda_i = c zeta_i \ omega_i varphi(x_i) + b + zeta_i - y_i = 0 end{cases} quad (28)
式中:lambda_i 为规划问题的对偶变量。构造如下满足Mercer定理的核函数:
K(x_i, x_j) = varphi(x_i) varphi(x_j) quad (29)
则优化问题可表示为式(30):
�egin{bmatrix} 0 & I_v^T \ I_v & Omega + c^{-1} I end{bmatrix} �egin{bmatrix} b \ lambda end{bmatrix} = �egin{bmatrix} 0 \ y end{bmatrix} quad (30)
式中:I_v = [1,1,dots,1]^T,共计i个元素,Omega_{ij} = k(x_i, x_j),i, j=1,2,dots,L。
3.2 评价指标
均方根误差(RMSE)和平均绝对误差(MAE)[13]用于评估预测模型的预测性能。定义式(31)和式(32)所示:
R_{ ext{MSE}} = sqrt{sum_{t=0}^T frac{(y_t^{ ext{true}} - y_t^{ ext{forecast}})^2}{T}} quad (31)
M_{ ext{AE}} = frac{sum_{t=0}^T y_t^{ ext{true}} - y_t^{ ext{forecast}}
}{T} quad (32)
式中:t为一次勘探时长;T为总时长;y_t^{ ext{forecast}} 和 y_t^{ ext{true}} 分别为时间步t的预测值和实际值。
4 深度强化学习算法
4.1 算法简介
本文选择深度强化学习算法中的深度确定性策略梯度算法进行计算和建模。深度确定性策略梯度算法综合考虑了确定性策略梯度算法[14]中的策略网络和深度Q网络中的经验回放以及评估网络和目标网络分离的技巧,在目标进行连续动作的环境中效果显著。
深度确定性策略梯度算法的步骤如下:
输入:Actor评估网络,参数为 heta;Critic评估网络,参数为varpi;Actor目标网络,参数为 heta';Critic目标网络,参数为varpi';衰减因子gamma;最大迭代次数T;批量梯度下降的样本数m;目标网络参数更新步数C;软更新权重系数 au。
输出:最优的Actor评估网络参数 heta,最优的Critic评估网络参数varpi。
随机初始化 heta、varpi,令 heta' = heta、varpi' = varpi,并清空经验回放集合D。从1到T(训练总回合)进行迭代。
(1) 初始化最初状态s;
(2) Actor评估网络基于状态s得到动作a = pi_ heta(s) + N;
(3) 执行动作a,得到新的状态s',奖励r,判断是否为终止状态done;
(4) 将{s, a, r, s', ext{done}}保存在经验回放集合D中;
(5) 在经验回放集合D中平均地选出m个样本{s, a, r, s', ext{done}}, i=1,2,dots,m,Actor目标网络根据s'输出a' = pi_{ heta'}(s') + N,Critic评估网络根据s, a输出当前Q值Q(s, a, varpi),Critic目标网络根据s', a'输出Q'(s', a', varpi'),计算目标Q值y_i:
y_i = �egin{cases} r_i & ext{is_end}=1 \ r_i + gamma Q'(s_i', a_i', omega') & ext{is_end}=0 end{cases}
(6) 以frac{1}{m}sum_{i=1}^m (y_i - Q(s_i, a_i, omega))^2作为均方差损失函数,用神经网络的梯度反向传播来替换Critic评估网络的参数varpi;
(7) 以J( heta) = -frac{1}{m}sum_{i=1}^m Q(s_i, a_i, omega)表示作为损失函数,用神经网络的反向传播来替换Actor评估网络的参数 heta;
(8) 若T \% C = 1,就用 heta' leftarrow au heta + (1- au) heta'、omega' leftarrow au omega + (1- au)omega'替换Critic目标网络和Actor目标网络的参数varpi'和 heta'。
(9) 如果s'显示为终止状态,那么这一轮的迭代到此结束,否则让s = s',并且重新回到步骤(2),继续迭代。
4.2 算法应用
首先,设置模型的参数。对于每个小时,储能系统运营商接收一小时前的电价和负荷需求,并对这些值进行预处理。更新输入向量和预处理数据后,运用LSSVM模型预测接下来几个小时的价格和负载需求。根据模型预测的数据,得到每小时的最优储能系统运行功率。设定刺激因子varphi、负荷状态相关因子(S_{ ext{OC_init}}, S_{ ext{OC_min}}, S_{ ext{OC_max}})和储能系统设计因子(P^{ ext{dis, min}}, P^{ ext{cha, min}}, C^{ ext{ESS}}, eta^{ ext{dis}}, eta^{ ext{cha}})的模型参数。在每个片段开始之前,初始化Q表和初始状态。初始状态s_0由预测值中初始时间段的电价与初始的负荷状态组成。储能系统功率的确定策略遵循勘探比贪婪策略,包括勘探和开采,如式(33)所示:
a_t = �egin{cases} ext{random } a_t in A_t & varepsilon > �eta \ operatorname{argmax}_{a_t in A_t} Q(s_t, a_t) & varepsilon leqslant �eta end{cases}
varepsilon = �egin{cases} varepsilon - varepsilon^{ ext{limit}} - varepsilon^{ ext{min}} & varepsilon > varepsilon^{ ext{min}} \ varepsilon^{ ext{min}} & varepsilon leqslant varepsilon^{ ext{min}} end{cases} quad (33)
式中:�eta in [0,1] 为随机确定的常数;varepsilon 为勘探比。
如果varepsilon大于�eta,则储能系统运营商执行随机行为的勘探;如果varepsilon小于�eta,则储能系统运营商执行开采,其行为对应于当前学习状态下Q函数的最大值。在训练的早期阶段,需要较高的探索率,通过随机行为尽可能多地更新Q函数。随着训练的进行,需要降低勘探率来开发计算值的模型。公式(34)显示了随着章节的迭代,探索比率是如何变化的:
varepsilon = �egin{cases} varepsilon - frac{varepsilon^{ ext{init}} - varepsilon^{ ext{min}}}{M} & varepsilon > varepsilon^{ ext{min}} \ varepsilon^{ ext{min}} & varepsilon leqslant varepsilon^{ ext{min}} end{cases} quad (34)
式中:varepsilon^{ ext{init}} 为初始勘探比;varepsilon^{ ext{min}} 为最小勘探比;M为勘探步长。
当varepsilon值大于varepsilon^{ ext{min}}时,varepsilon值随迭代次数的增加而减小。由于优化得到的结果可能是局部极大值而不是全局极大值,因此设置了最小勘探比varepsilon^{ ext{min}}。
基于勘探比贪婪策略选择储能系统运行功率后,运营商立即从电力市场(环境)获得奖励r_{t+1},并观察下一个状态s_{t+1}。然后更新Q函数,使用状态动作转换(s_t, a_t, r_{t+1}, s_{t+1})。这个过程不断重复,直到达到最后一个时间步骤的状态s_{t+1}为止。整个时间步长迭代持续到一个片段,并且这个迭代被重复,直到达到片段的数量N。储能系统运营商仅将当前小时对应的时间步长t_0的动作作为最优功率。算法继续到下一个小时,重复上述过程直到最后一个小时。
5 仿真和结果
5.1 测试场景
以来自美国宾夕法尼亚-新泽西-马里兰(PJM)电力市场的电价和负荷需求的历史数据进行测试。其中,以每小时PJM-RTO节点数据作为电价,以地区每小时耗电量数据作为负荷需求。采用表1中总结的参数进行储能系统建模。
表1 储能系统模型参数
参数 值 说明
ESS容量C^{ ext{ESS}}/MWh 95 自给时间满足3小时
P^{ ext{cha, max}}/MW 0.25 C^{ ext{ESS}}
P^{ ext{dis, max}}/MW E^{ ext{load,min}} 用户负荷需求
ESS充电效率eta^{ ext{cha}} 0.95 磷酸铁锂电池
ESS放电效率eta^{ ext{dis}} 0.95 磷酸铁锂电池
SOC最小值S_{ ext{OC_min}} 0.2 磷酸铁锂电池
SOC最大值S_{ ext{OC_max}} 0.8 磷酸铁锂电池
SOC初始状态S_{ ext{OC_init}} 0.2
测试选定的地区为EASTON[15],该地区位于美国伊利诺伊州梅森郡的一个城镇,占地62公顷,有居民373人,城镇内部无自主发电设备。储能的容量被设定为:以在缺乏电网供电的情况下,为地区提供3h的电力。结合相关数据,储能系统的容量设定为95 MWh。储能类型是锂离子电池,与锂离子电池耐久性相关的每一个值,如P^{ ext{dis, max}}, P^{ ext{cha, max}}、S_{ ext{OC_min}}和S_{ ext{OC_max}},都是根据锂离子电池界推荐的通用做法来选择的。将P^{ ext{dis, max}}设为预测负荷需求中的最小值,以避免供电量超过机组负荷需求。在这个时候,P^{ ext{dis, max}}被限制为不超过1.0C-rate,考虑到耐久性,功率之间的间隔设置为1.0 MW。eta^{ ext{cha}}和eta^{ ext{dis}}是参照传统锂离子电池的往返效率来确定的。将SOC的初始状态设置为0.2,以分析白天进行充电和放电的情况。非高峰/中高峰/高峰时段的激励因子varphi_t列于表2,根据电网和用户的特性、储能系统类型和设计条件,上述参数的值可能有所不同。
表2 不同时期的激励因素
周期 时间 激励因子
非高峰 00:00-06:00, 22:00-23:00 0.4
中高峰 07:00-16:00 0.2
高峰 17:00-21:00 0.1
5.2 优化结果
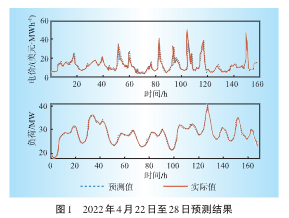
通过最小二乘支持向量机,对PJM电力市场2022年4月22日至2022年4月28日的数据进行预测。将预测的电价和负荷需求与实际值进行比较,结果如图1所示。使用均方根误差和平均绝对误差两个指标对预测准确性的进行定量评估,对比结果如表3所示。本文的LSSVM模型显示出较低的平均绝对误差值,证明了模型设置和训练的合理有效性。通过对比误差值可得出结论:LSSVM模型预测负荷数据的性能优于电价的预测性能。
图1 2022年4月22-28日的预测结果
(原文图示:展示电价和负荷的预测值与实际值对比曲线)
表3 LSSVM模型预测结果定量评价
均方根误差 平均绝对误差
电价预测模型 0.2129 0.1368
负荷预测模型 0.0628 0.0475
表4总结了用于Q学习的超参数,这些超参数是根据RL算法的常见应用选择的。
表4 强化学习的超参数
超参数 值
贴现因子gamma 0.99
学习率alpha 0.5
初始探索率varepsilon^{ ext{init}} 1.0
最小探索率varepsilon^{ ext{min}} 0.001
勘探步骤M 250000
片段N 300000
为了确认学习过程是否通过应用此算法得到了良好的执行,调查了片段奖励如图2所示。片段奖励是EO的一天收入。图2(a)显示了在应用奖励刺激之前的学习过程,图2(b)显示了在4月22日应用奖励刺激之后的学习过程。如图2所示,在学习开始时,代理探索并显示了一个较低的事件奖励值,随着学习的进展,此事件奖励的值增加并最终收敛。实施刺激后,收敛值大于实施刺激前的值,这意味着在实施刺激后进行学习以获得更多利润。
图2 训练期间片段奖励的收敛性
(原文图示:展示有无激励下的奖励收敛曲线)
在最初的学习阶段,当一天中的许多时间点超过SOC限制时,会出现事件奖励明显较小的情况。当幕迭代超过勘探步骤M时,varepsilon值即勘探比率收敛到varepsilon^{ ext{min}}。然后进行额外的50000次开采迭代,以获得最终收敛值,如图2所示。即使在250000次开采之后,有时,由于勘探是以varepsilon^{ ext{min}}的最小勘探比率进行的,因此,开采的回报也低于收敛值。在整个学习过程之后,得出了ESS的最优输出功率。
为了确认应用该算法学习过程是否完成良好,本文对储能系统的充放电量进行了调查,如图3所示。图3显示了4月22日应用奖励激励前后的充放电量对比情况。结果显示,在学习开始时,运营商勘探并显示了一个较低的片段奖励值(片段奖励即为一段时间内的即时奖励集合,案例中对应的即为储能系统运营商一天24h内的即时奖励之和),随着学习的进展,该片段奖励的价值增加并最终趋同。在应用激励后,储能充放电量大于应用激励前的值,这意味着学习是为了在应用激励后获得更多的利润。
图3 激励前后储能系统充放电量对比
(原文图示:展示有无激励下的充放电功率曲线)
在施加激励的情况下,在非峰段充电相对较多,在峰段放电较多。这是由于激励因子从非高峰时期增加到高峰时期,储能系统运营商获得更直接的奖励r_{t+1}而得到的结果。高电价通常意味着整个电网处于高负荷需求中。因此,从整个电网的角度来看,所提出的激励整合套利策略有效地将电网的峰值电力负荷分配到较低的峰值。
图4为2022年4月22日电网运营商峰时供电对比结果图,电网运营商日间提供的总电量几乎相同,然而,以降低峰值功率为重点,当采用基本的储能盈利策略时,约节省了17.5%。当施加激励策略时,与原本相比节约了30.3%的电量。
图4 运营商峰时供电对比结果
(原文图示:展示有无激励下的电网供电曲线)
相比于未加激励的情况,储能系统参与市场交易的意愿大大增加,政府能够更多地将用电高峰期转移到非用电高峰期。综合考虑这些结果,因此可以得出结论:激励整合盈利对储能系统运营商的利润和电网可靠性是一个双赢的策略。
6 结束语
本文提出了一种考虑激励策略的储能系统盈利模式,并进行了案例验证。结果显示,该激励策略对储能系统运营商和电网运营商来说都是有利的。它也可以通过峰谷套利以及激励机制,给储能系统运营商带来更高利润;降低电网峰时供电压力。但是并未考虑政府对储能系统的补贴政策以及新能源装机补贴等问题,所以还需要进一步的研究和完善。
参考文献
[1] 葛兴凯. 储能系统盈利模式及应用实例分析[J]. 新型工业化, 2021, 11(8): 168-169, 171.
[2] 刘坚. 适应可再生能源消纳的储能技术经济性分析[J]. 储能科学与技术, 2022, 11(1): 397-404.
[3] 党晓圆, 赖伟. 基于能量套利的储能价值评估模型[J]. 现代电子技术, 2021, 44(23): 180-186.
[4] ZAKERI B, SYRI S. Electrical energy storage systems: A comparative life cycle cost analysis[J]. Renewable & Sustainable Energy Reviews, 2015, 56: 549-596.
[5] FU Q, MONTOYA L F, SOLANKI A, et al. Microgrid generation capacity design with renewables and energy storage addressing power quality and surety[J]. IEEE Transactions on Smart Grid, 2012, 3(4): 2019-2027.
[6] KRISHNAMURTHY D, UCKUN C, ZHOU Z, et al. Energy storage arbitrage under day-ahead and real-time price uncertainty[J]. IEEE Transaction on Power System, 2018, 33: 84-93.
[7] WANG H, ZHANG B S. Energy storage arbitrage in real-time markets via reinforcement learning[C]. in IEEE Power & Energy Society General Meeting, New York, 2018.
[8] ZHAO H, WU Q, HU S, et al. Review of energy storage system for wind power integration support[J]. Applied Energy, 2015, 137: 545-553.
[9] FLEGKAS S, BIRKELBACH F, WINTER F, et al. Profitability analysis and capital cost estimation of a thermochemical energy storage system utilizing fluidized bed reactors and the reaction system MgO/Mg(OH)2[J]. Energies, 2019, 12(24): 4788.
[10] SUN W Q, ZHANG J, ZENG P L, et al. Energy storage configuration and day-ahead pricing strategy for electricity retailers considering demand response profit[J]. International Journal of Electrical Power & Energy Systems, 2022, 136: 142-615.
[11] 虞启辉, 田利, 李晓飞, 等. 考虑风能不确定性的压缩空气储能容量配置及经济性评估[J]. 储能科学与技术, 2021, 10(5): 1614-1623.
[12] 郑伟立, 何茹玥, 李垣彤, 等. 基于“套利”视角的储能产业商业逻辑研究[J]. 发展研究, 2021, 38(4): 18-24.
[13] 周磊, 吴辉, 嵇文路, 等. 微电网脆弱性预评估方法[J]. 电力需求侧管理, 2018, 20(1): 20-24.
[14] 魏小曼, 余昆, 陈星莺, 等. 基于Affinity propagation和K-means算法的电力大用户细分方法分析[J]. 电力需求侧管理, 2018, 20(1): 15-19, 35.
[15] 王一, 马子明, 谭跃凯, 等. 广东日前电力市场方案设计与市场仿真[J]. 电力需求侧管理, 2018, 20(1): 10-14.




