摘要:论文《两阶段域适应神经机器翻译方法》发表在《 厦门大学学报(自然科学版) 》,版权归《厦门大学学报(自然科学版)》所有。本文来自网络平台,仅供参考。 [目的] 为了提升神经机器翻译模
论文《两阶段域适应神经机器翻译方法》发表在《厦门大学学报(自然科学版)》,版权归《厦门大学学报(自然科学版)》所有。本文来自网络平台,仅供参考。
[目的] 为了提升神经机器翻译模型的迁移学习效果,以语言数据为中心开展域适应方法探索。[方法] 根据KL散度和最大均差两种域适应量度的定量分析结果,提出一种针对拥有大规模平行句子和小规模域文本场景的两阶段减量学习框架。第1阶段域过滤,利用域文本过滤平行句子,得到域平行句子,再利用得到的域平行句子训练出域神经机器翻译模型。第2阶段质量过滤,利用训练出的域神经机器翻译模型将第1阶段过滤出的域平行句子翻译一遍,比较机器译文与人工译文的质量,删除低质量平行句子以获得高质量域平行句子。最后利用得到的高质量域平行句子训练出优化的域神经机器翻译模型。[结果] 在适应法律域英汉神经机器翻译上的实验结果显示,新提出的两阶段算法只需原来训练步的四分之一左右,反而可以提高2个多的BLEU分数。[结论] 实验结论证明减量学习框架能够在大大减少训练时空开销的前提下获得最优的性能,最终实现神经机器翻译模型的快速域迁移。
关键词
域适应;域适应量度;减量学习;神经机器翻译;法律域
引言
近段时间以来,基于多层神经网络的深度学习算法已经能够从大规模双语平行句对数据中训练得到译文质量很高的神经机器翻译(neural machine translation, NMT)模型。得益于向量计算部件拥有的超级并行算力、多层神经网络捕获的深度语义特征以及平行语言大数据蕴含的宽背景上下文知识,富资源通用NMT得到了充分的研究,产生了一系列优秀算法、数据资源和实用工具[1]。随着语言大数据爆炸增长,富资源机器翻译研究更加关注迁移学习(transfer learning)方法,正朝着域适应(domain adaptation)方向迈进。
迁移学习是一个机器学习问题。机器学习往往包含源域(source domain, Ds)和目标域(target domain, Dt)、源任务(source task, Ts)和目标任务(target task, Tt)两组成对的源目概念。在描述机器学习数据时,习惯用训练(样本)集和测试(样本)集概念来对应源域和目标域。通常的机器学习是双同构的,也就是域相同(Ds=Dt)且任务相同(Ts=Tt)。而迁移学习则是异构机器学习,即域不同(Ds≠Dt)或任务不同(Ts≠Tt),亦或二者皆不同。具体而言,迁移学习致力于利用源域Ds和源任务Ts来提高目标域Dt和目标任务Tt的机器学习效果。
域适应是一种特殊的迁移学习,即任务相同(Ts=Tt),例如都是机器翻译任务,但域不同(Ds≠Dt),例如训练集是通用的广域英汉句对,而测试集是法律域英汉句对。在描述域适应时,还习惯用域外(out-domain)和域内(in-domain)概念来对应迁移学习的源域和目标域。域适应中的域不同可以具体表现为源域和目标域的数据分布不一致,也可以表现为存在大量带标签的域外样本,而域内带标签的样本没有或者极少。
域适应机器翻译研究旨在探索如何利用信息丰富的域外样本提升域内机器翻译模型的性能。因为训练集和测试集的数据分布不一致时,通常机器学习出的模型往往会过拟合源域,从而降低了在目标域上的泛化性。众所周知,在机器翻译或人工翻译将一种符号转化成另一种符号的过程中,都会面临域专有词表、域特有表达等域相关的问题。理想的域适应机器翻译能够根据域快速得到合适的机器翻译模型。
1 相关研究
回顾域适应研究历史,早在统计机器翻译时期就产生了大量研究成果[2]。当前,域适应NMT研究继承和发展了域适应统计机器翻译的两种主要思路[3]。一是以模型为中心(model-centric)改进神经网络,通过干预神经网络的架构、训练以及解码实现域适应。另一是以数据为中心(data-centric)挑选域相关的训练样本,包括充分发挥域内单语数据、域外高质量平行数据以及未知质量平行数据的规模优势等。由于以模型为中心也会使用到单语或平行数据,所以上述两种思路之间也存在交叠。
1.1 以模型为中心的研究
以模型为中心的思路注重深度学习算法的改进,代表性研究主要包括:
1. 干预神经网络架构:Tobias等[4]提出一种适用于域内单语数据的技术,即联合训练域语言模型和NMT模型的深融合(deep fusion)技术。Britz等[5]提出了一种适用于多域数据的技术,即在编码器(encoder)顶部添加前馈神经网络(feedforward neural network, FNN)并利用注意力预测源句域的域判别器(discriminator)技术。Kobus等[6]提出将词级特征(word-level features)附加到NMT的嵌入(Embedding)层来控制域并预测源句域标签。
2. 干预神经网络训练:Chen等[7]使用域分类器修改NMT代价函数,将域分类器输出概率转化为域权重,使用验证数据训练该分类器。后续Wang等[8]提出了NMT句子选择和加权的联合框架。Varga[9]将微调(fine tuning)应用于从可比语料中提取的平行数据。为防止域内数据微调后域外退化,后续Praveen等[10]提出了一种保持域外模型分布的基于知识蒸馏的扩展微调技术。Dou等[11]直接学习出源域和目标域之间的差异,并利用该差异改进模型的训练。Chu等[12]集成多域和微调,提出一种混合微调(mixed-fine tuning)技术,较好地解决了因域内数据量小而导致的微调过拟合问题。此外,针对微调过程中的过拟合问题,Miceli等[13]探索了正则化(regularization)技术。
3. 干预神经网络解码:Adams等[14]提出一种浅融合(shallow fusion)解码算法,先在大规模单语数据上训练语言模型,然后结合语言模型与预训练的NMT模型,加权评估概率以生成下一个单词。该算法可以用于低资源域适应NMT。Freitag等[15]提出将域外模型和微调后的域内模型集成解码。Khayrallah等[16]提出了一种基于堆栈(stack-based)的词格(word lattices)解码算法。在域适应实验中,词格由统计机器翻译生成,最终的解码效果优于传统解码。
1.2 以数据为中心的研究
以数据为中心的思路更加适合快速实现工程应用,代表性研究主要包括:
1. 利用域内单语数据:域内单语数据不易直接用于NMT的语言模型,Currey等[17]将目标域单语数据复制到源域,并使用复制的数据训练NMT。Zhang等[18]使用双语词典和单语数据通过预测翻译和句子排序多任务学习来加强NMT编码器。Cheng等[19]利用NMT作为自编码器对单语数据进行重构,将源域单语数据和目标域单语数据同时用于NMT。
2. 利用域外高质量平行数据:通过利用大规模高质量平行数据训练得到通用机器翻译模型,再迁移到特定目标域。相关研究与以模型为中心的干预神经网络训练研究中微调、混合微调有交叠。Wang等[20]将统计机器翻译中的数据选择(data selection)思想用于NMT,根据句子嵌入相似性(sentence embedding similarity)从域外数据中选择接近域内数据的句子。Van Der Wees等[21]提出了一种动态数据选择方法,在NMT的不同训练阶段采用不同的训练样本集。
3. 利用未知质量平行数据:对于互联网上的富资源语言,比较容易获得大规模平行句子。这些包含多域的平行句子混在一起反而与某个具体域关联度不显著,更有甚者还有可能包含错误[22]。对同时针对某个具体域的情况,Hu等[23]已经拥有一定规模的单语或双语域词集、域文本文档等资源。刘欢等[24]从多域的平行句子中挑选高质量旅游域平行句子进行数据增强。上述场景比较接近真实应用中的数据环境,如何利用这类未知质量的平行数据,实现适应具体域的NMT是一个更具体、更实用的研究问题。围绕该研究问题,我们定量分析了两种域适应量度,尝试提出一种两阶段减量学习新思路。
2 域适应量度
为了定量计算源域与目标域之间的适应程度,首先计算源域数据词表Vs和目标域数据词表Vt的并集(V={v_{1}, v_{2}, cdots, v_{n}}),接着根据n维向量基V分别统计得到源域数据的词频向量(S={s_{1}, s_{2}, cdots, s_{n}})和目标域数据的词频向量(T={t_{1}, t_{2}, cdots, t_{n}}),最后采用统计学上的KL散度(kullback-leibler divergence, KLD)和最大均差(maximum mean discrepancy, MMD)来衡量源域与目标域的差异程度。
2.1 KL散度
两个词频向量S与T的散度公式如下:
2.2 最大均差
两个词频向量S与T的最大均差公式(采用高斯核函数(k(x, y))改写后的可计算版本)如下:
最大均差是迁移学习尤其是域适应算法中使用最广泛的一种损失函数,主要用来度量两个不同但相关的分布之间的距离[26]。
2.3 量度分析
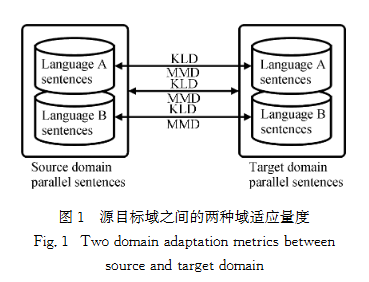
由于迁移学习任务是机器翻译,因此还存在两对源目标概念。如图1所示,源域和目标域的数据都是平行句对,而根据机器翻译方向,源语言是A而目标语言是B。分别统计出源域A语言句对与目标域A语言句对之间的KLD和MMD、源域B语言句对与目标域B语言句对之间的KLD和MMD以及源域平行句对与目标域平行句对之间的KLD和MMD。
对已有的3组英汉平行句子语料进行了统计分析。其中LAW07语料包含源域21942400句对,LAW08语料包含源域5899520句对,LAW09语料包含源域5710080句对,这3组语料都包含完全相同的目标域50000句对。得到英汉语料域适应量度数值如表1所示(表中数值为乘以(10^6)后的结果)。
表1 英汉语料域适应量度
| 源语料(句对数) | 目标语料(句对数) | KLD×10⁶ | MMD×10⁶ |
| LAW07.train.eng(21942400) | LAW07.test.eng(50000) | 11.028 | 21.935 |
| LAW08.train.eng(5899520) | LAW08.test.eng(50000) | 1.144 | 4.292 |
| LAW09.train.eng(5710080) | LAW09.test.eng(50000) | 1.098 | 2.384 |
| LAW07.train.zho(21942400) | LAW07.test.zho(50000) | 93.858 | 262.260 |
| LAW08.train.zho(5899520) | LAW08.test.zho(50000) | 9.254 | 99.182 |
| LAW09.train.zho(5710080) | LAW09.test.zho(50000) | 8.911 | 69.141 |
| LAW07.train.engzho(43884800) | LAW07.test.engzho(100000) | 41.145 | 30.041 |
| LAW08.train.engzho(11799040) | LAW08.test.engzho(100000) | 4.695 | 20.027 |
| LAW09.train.engzho(11420160) | LAW09.test.engzho(100000) | 4.297 | 19.550 |
表1中的数值表明,无论从英语、汉语各自单语视角还是从英汉双语视角看,LAW09语料源域和目标域更加接近。分析表1数值可知,语料规模越大,域适应性不一定更强,规模最大的LAW07语料域适应性最差,规模最小的LAW09语料域适应性最好。
3 减量学习
在上一节域适应量度统计分析结果的启发下,探索一种工程级减量学习新思路,以数据为中心,充分发挥未知质量平行数据的规模优势,实现高效域NMT。
3.1 框架
减量学习框架如图2所示,主要包括域过滤器(domain filter)、质量过滤器(quality filter)以及3个相同的NMT训练器(NMT trainer)。执行该框架的前置数据包括通用平行句子(common parallel sentences)和域文本资源(domain text resources)。其中,通用平行句子是指大规模、易获得、域不明确(也可能是多域相关)、可能包含错误的双语数据;而域文本资源可以是单语或双语数据,例如域词集、域文本文档等。
上述减量学习框架是一种独立于具体的过滤算法、机器翻译算法、源语言目标语言的元框架。以法律域英汉机器翻译为例,描述减量学习框架的执行过程:
1. 第1阶段减量学习:域过滤器根据域文本资源对通用平行句子中的每对句子进行属于法律域和不属于法律域的二值分类,最终过滤得到域平行句子(domain parallel sentences)。接着利用NMT训练器分别在通用平行句子和域平行句子上训练得到通用英汉NMT模型和法律域英汉NMT模型。
2. 第2阶段减量学习:先采用法律域英汉NMT模型翻译域平行句子中的每个英语句子,接着在质量过滤器中调用莱文斯坦(levenshtein)字符串距离函数,计算原有汉语句子与机器翻译输出的汉语句子之间的相似度,根据预设阈值过滤掉相似度较低的句对,最终得到高质量域平行句子(high quality domain parallel sentences)并再次训练得到优化的法律域英汉NMT模型。此处预设阈值为0.9,以保证过滤的严格性。
整个框架能够训练出3个英汉NMT模型,其中通用英汉NMT模型仅用于实验对比参照。
3.2 算法
围绕实际的域适应NMT需求,根据减量学习框架设计了两阶段减量学习NMT算法,具体流程如图3所示。
算法说明:
输入:初始训练集(train,通用平行句子)、开发集(dev,域平行句子)、测试集(test,域平行句子)、域文本资源(dtr)。
输出:优化的域NMT模型(odnmt)。
核心步骤:
1. 第7行:训练通用NMT模型(cnmt),仅用于对比。
2. 第8行:通过域过滤器(DomainFilter.filter)从通用平行句子中筛选出域平行句子(train)。
3. 第9行:利用域平行句子训练域NMT模型(dnmt)。
4. 第11-14行:使用域NMT模型翻译域平行句子中的源语言句子,得到机器译文(mtout)。
5. 第15行:通过质量过滤器(QualityFilter.filter)对比机器译文与人工译文,筛选出高质量域平行句子(train)。
6. 第16行:利用高质量域平行句子训练优化的域NMT模型(odnmt)。
关键实现:
NMT训练器(NMTTrainer.train):采用基于注意力机制的编码器-解码器实现①。
域过滤函数(DomainFilter.filter):采用基于字符串-频率索引(string-frequency index, SFI)的文本分类(SFITC)算法实现[27],适合短文本过滤,时空效率高。
质量过滤函数(QualityFilter.filter):采用集成机器翻译过滤算法实现[28],调用莱文斯坦字符串距离函数计算句子相似度,工程实现简单。
4 实验
为了验证减量学习的有效性与高效性,进行了法律域英汉NMT实验。
4.1 实验环境与数据
4.1.1 示范验证系统
根据减量学习框架实现了两阶段减量学习NMT算法,集成的基于注意力机制的编码器-解码器超参数如下:神经元数(num_units=512)、编码器/解码器层数(num_encoder_layers=num_decoder_layers=4)、训练轮数(epoch=10)、批量规模(batch_size=128)、束搜索宽度(beam_width=10),其他参数保持缺省值。最终增加交互界面实现Web服务器,通过互联网发布英汉NMT应用①。
4.1.2 实验数据制备
域过滤器构建:抓取英语法律词汇76792条,构建法律域双语词集;抓取汉英法律文本及学术论文,得到1346519条法律域双语句集;抓取其他域学术论文,构建2850764条其他域双语句集。
平行句库:人工构建100000对英汉法律域平行句子,等分为开发集(50000句对)和测试集(50000句对)。
训练集:收集整理21942400对英汉平行句子(LAW07语料)作为初始训练集,经两阶段减量学习后得到LAW08语料(5899520句对)和LAW09语料(5710080句对)。
预处理:汉语句子处理为空格分割的单字,英语句子处理为空格分割的小写单词。
4.2 实验结果与分析
4.2.1 基础实验结果
英汉NMT实验结果如表2所示,采用BLEU(BLEU4)、chrF2、TER三个指标评价模型性能(BLEU和chrF2数值越大越好,TER数值越小越好)。
表2 英汉NMT模型结果
| 语料 | 训练集句对数 | 训练集词表规模 | 训练集Token数 | 训练步数 | BLEU | chrF2 | TER |
| LAW07 | 21942400 | 326515 | 479825064 | 1714250 | 45.41 | 38.62 | 40.21 |
| LAW08 | 5899520 | 157432 | 136738636 | 460900 | 47.13 | 40.14 | 40.13 |
| LAW09 | 5710080 | 152340 | 133156728 | 446100 | 47.88 | 40.77 | 38.99 |
结果分析:
两阶段减量学习减少了训练语料规模,但模型性能持续提升,LAW09语料训练的模型各项指标最优。
训练步数大幅减少,LAW09的训练步数仅为LAW07的四分之一左右,验证了减量学习的高效性。
4.2.2 学习曲线分析
英汉NMT实验的3个NMT模型训练过程中的学习曲线如图5所示(横坐标为训练步,纵坐标为BLEU)。
结果分析:训练步最少的LAW09模型BLEU值最高,说明减量学习能够在减少训练开销的同时,获得更优的模型性能。
4.2.3 BPE预处理实验
采用BPE(byte pair encoding)子词切分工具①对3组语料中的英语句子进行32k词表预处理后,重新训练NMT模型,实验结果如表3所示。
表3 基于BPE的英汉NMT模型结果
| 语料 | 训练集句对数 | 训练集词表规模 | 训练集Token数 | 训练步数 | BLEU | chrF2 | TER |
| LAW07.BPE | 21942400 | 32134 | 490060812 | 1714250 | 46.75 | 39.36 | 39.08 |
| LAW08.BPE | 5899520 | 32033 | 139420536 | 460900 | 48.02 | 40.73 | 39.34 |
| LAW09.BPE | 5710080 | 32018 | 135699728 | 446100 | 48.69 | 41.24 | 38.25 |
结果分析:
BPE预处理压缩了词表规模,有效处理未登录词问题,所有模型性能均有所提升。
两阶段减量学习框架对采用BPE预处理的模型依然有效,LAW09.BPE模型性能最优,验证了框架的通用性。
4.3 实验结论
综合域适应量度统计结果与法律域英汉NMT实验结果,得出以下结论:
1. 法律域英汉NMT模型的BLEU评分排序与语料的KLD和MMD数值排序完全吻合,验证了KL散度和最大均差能够有效定量度量域适应NMT中源域与目标域语料的适应程度。
2. 减量学习是有效的域适应策略:域过滤增强了训练语料的域适应性,质量过滤提高了训练语料的域相关译文质量。
3. 两阶段减量学习NMT算法只需原来训练步的四分之一左右,即可提高2个多的BLEU点,验证了减量学习框架能够高效达到最优NMT性能。
4. 对于域NMT模型训练,关键在于高质量域相关语料,而非单纯追求语料规模,减量学习为从大规模未知质量语料到高质量域相关语料的数据工程提供了有益尝试。
5 结论
围绕域适应NMT问题,采用以数据为中心的思路,充分发挥未知质量平行数据的规模优势,通过域过滤和质量过滤两阶段提高平行数据的域关联度和译文质量。最终在减量学习元框架下集成基于注意力机制的编码器-解码器用以实现NMT训练器,并在法律域英汉机器翻译实验中验证了所提减量学习的效果。
下一步研究主要关注域知识建模和域知识干预NMT模型研究:准备构建显式的多语言域知识图谱,增强跨语言复杂域知识的神经可计算性,进一步提升域适应NMT的译文质量;在减量学习元框架中试验语义过滤和形态语义集成过滤等更具性能潜力的算法,并将相关研究成果迁移到其他适合的域NMT应用当中。
参考文献
[1] TAN Z X, WANG S, YANG Z H, et al. Neural machine translation: a review of methods, resources, and tools[J]. AI Open, 2020, 1: 5-21.
[2] 崔磊, 周明. 统计机器翻译领域自适应综述[J]. 智能计算机与应用, 2014, 4(6): 31-34.
[3] CHU C H, WANG R. A survey of domain adaptation for neural machine translation[C]∥Proceedings of the 27th International Conference on Computational Linguistics. [S. l.]: ICCL, 2018: 1304-1319.
[4] TOBIAS D, FELIX H. Using target-side monolingual data for neural machine translation through multi-task learning[C]∥Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. [S. l.]: EMNLP, 2013: 1500-1505.
[5] BRITZ D, LE Q, PRYZANT R. Effective domain mixing for neural machine translation[C]∥Proceedings of the Second Conference on Machine Translation. Copenhagen: Association for Computational Linguistics, 2017: 118-126.
[6] KOBUS C, CREGO J, SENELLART J. Domain control for neural machine translation[C]∥Proceedings of the International Conference Recent Advances in Natural Language Processing. [S. l.]: ICRANLP, 2016: 372-378.
[7] CHEN B X, CHERRY C, FOSTER G, et al. Cost weighting for neural machine translation domain adaptation[C]∥Proceedings of the First Workshop on Neural Machine Translation. Vancouver: Association for Computational Linguistics, 2017: 40-46.
[8] WANG R, UTIYAMA M, FINCH A, et al. Sentence selection and weighting for neural machine translation domain adaptation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(10): 1727-1741.
[9] VARGA Á. Domain adaptation for multilingual neural machine translation[C]∥Computer Science, Linguistics. [S. l.]: CSL, 2017: 64478408.
[10] PRAVEEN D, CHRISTOF M. Fine-tuning for neural machine translation with limited degradation across in-and out-of-domain data[C]∥Proceedings of the 16th Machine Translation Summit. [S. l.]: MTS, 2017: 156-169.
[11] DOU Z Y, WANG X Y, HU J J, et al. Domain differential adaptation for neural machine translation[C]∥Proceedings of the 3rd Workshop on Neural Generation and Translation. Hong Kong: Association for Computational Linguistics, 2019: 59-69.
[12] CHU C H, DABRE R AJ, SADAO K. An empirical comparison of domain adaptation methods for neural machine translation[C]∥Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: Association for Computational Linguistics, 2017: 385-391.
[13] MICELI B A V, HADDOW B, GERMANN U, et al. Regularization techniques for fine-tuning in neural machine translation[C]∥Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: Association for Computational Linguistics, 2017: 1489-1494.
[14] ADAMS V, SUBRAMANIAN S, CHRZANOWSKI M, et al. Finding the right recipe for low resource domain adaptation in neural machine translation[EB/OL]. (2022-01-02)[2023-12-01]. http:∥arxiv.org/abs/2206.01137.
[15] FREITAG M, AL-ONAIZAN Y. Fast domain adaptation for neural machine translation[EB/OL]. (2016-12-20)[2023-12-01]. http:∥arxiv.org/abs/1612.06897.
[16] KHAYRALLAH H, KUMAR M, DU H, et al. Neural lattice search for domain adaptation in machine translation[C]∥Proceedings of the Eighth International Joint Conference on Natural Language Processing. Taipei: AFNLP, 2017: 20-25.
[17] CURREY A, MICELI BARONE A V, HEAFIELD K. Copied monolingual data improves low-resource neural machine translation[C]∥Proceedings of the Second Conference on Machine Translation. Copenhagen: Association for Computational Linguistics, 2017: 148-156.
[18] ZHANG J J, ZONG C Q. Bridging neural machine translation and bilingual dictionaries[EB/OL]. (2016-10-24)[2023-12-01]. http:∥arxiv.org/abs/1610.07272.
[19] CHENG Y, XU W, HE Z J, et al. Semi-supervised learning for neural machine translation[C]∥Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: Association for Computational Linguistics, 2016: 1965-1974.
[20] WANG R, FINCH A, UTIYAMA M, et al. Sentence embedding for neural machine translation domain adaptation[C]∥Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: Association for Computational Linguistics, 2017: 560-566.
[21] VAN DER WEES M, BISAZZA A, MONZ C. Dynamic data selection for neural machine translation[C]∥Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: Association for Computational Linguistics, 2017: 1400-1410.
[22] SAUNDERS D. Domain adaptation and multi-domain adaptation for neural machine translation: a survey[EB/OL]. (2021-04-14)[2023-12-01]. http:∥arxiv.org/abs/2104.06951.
[23] HU J J, XIA M Z, NEUBIG G, et al. Domain adaptation of neural machine translation by lexicon induction[C]∥Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence: Association for Computational Linguistics, 2019: 2989-3001.
[24] 刘欢, 刘俊鹏, 黄锴宇, 等. 面向低资源俄汉机器翻译的领域适应方法[J]. 厦门大学学报(自然科学版), 2022, 61(4): 654-659.
[25] TUAN NGUYEN A, TOAN T, YARIN G, et al. KL guided domain adaptation[EB/OL]. (2021-01-14)[2023-12-01]. https:∥arxiv.org/abs/2106.07780v2.
[26] WANG W, LI H J, DING Z M, et al. Rethink maximum mean discrepancy for domain adaptation[EB/OL]. (2020-07-01)[2023-12-01]. http:∥arxiv.org/abs/2007.00689.
[27] LIU W Y, WANG L, YIM Z, et al. Active multi-field learning for spam filtering[J]. Comput Informatics, 2015, 33: 1400-1427.
[28] LIU W Y, WANG L. Ensemble machine translation to filter low quality corpus[C]∥2022 International Conference on Asian Language Processing (IALP). Singapore: IEEE, 2022: 500-504.
[29] 刘伍颖, 王挺. 结构化集成学习垃圾邮件过滤[J]. 计算机研究与发展, 2012, 49(3): 628-635.
[30] POPOVIĆ M. chrF: character n-gram F-score for automatic MT evaluation[C]∥Proceedings of the Tenth Workshop on Statistical Machine Translation. Lisbon: Association for Computational Linguistics, 2015: 392-395.
[31] POST M. A call for clarity in reporting BLEU scores[C]∥Proceedings of the Third Conference on Machine Translation: Research Papers. Brussels: Association for Computational Linguistics, 2018: 186-191.
[32] SENNRICH R, HADDOW B, BIRCH A. Neural machine translation of rare words with subword units[C]∥Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin: Association for Computational Linguistics, 2016: 1715-1725.




